LSR / Недоступность базы данных хостинга / 08.09.24
Описание
// вкратце что произошло//
8 сентября за несколько часов мы получили кратный прирост используемого места на диске на нашем кластере базы данных percona xtradb. Это было связано с механизмом pterodactyl, который сохраняет все логи пользователей об авторизации, загрузке, изменении, удалении файлов.
Предпринятые действия
// таймлайн с описанием //
- 08.09.24 20:00 начинается рост нагрузки по сети на кластер баз данных
- 09.09.24 02:00 все три ноды из кластера становятся недоступными в связи с накопившейся очередью репликации
- 09.09.24 10:00 стабилизация работы кластера и начало поиска проблем
- 10.09.24 17:20 пытаемся выполнить ряд команд для очистки данных в таблице, получаем недоступность кластера опять
- 10.09.24 19:20 восстановление кластера и планирование регламентных работ по переносу базы
- 11.09.24 12:00 повторение инцидента, которое привело к недоступности всех нод в кластере баз данных
- 11.09.24 21:00 начинаем миграцию данных на новый кластер
- 11.09.24 23:50 заканчиваем миграцию и пускаем пользователей
- 03.09.24 12:00 дропаем таблицу с activity logs, проверяем работоспособность и завершаем инцидент
Анализ
// анализ описания //
8 сентября в 20:00 один клиент решил загрузить свой сервер через sftp. Механизм логирования pterodactyl такой, что все действия, связанные с сервером, логируются. В связи с этим любая загрузка любого файла по sftp или через сайт приводит к созданию новой строки в таблице. У нашего клиента сервер имел dynmap, и, проанализировав логи, мы увидели, что в одном поле в таблице содержится порядка десяток тысяч символов в одной строке, все эти символы - пути и части файлов, которые генерируются dynmap.
Так как у клиента сервер имел довольно большой объем, загрузка шла несколько часов, и в связи с этим мы генерировали сотни INSERT в таблицу activity_logs в нашу панель. В архитектуре
percona xtradb используется синхронная репликация, которая дожидается записи всех данных на все слейвы и после этого подхватывает следующую запись. Мы столкнулись с ростом очереди на
INSERT, а впоследствии это привело к отставанию слейвов от мастера и остановке работы кластера, так как он потерял кворум.
С 09.09 до 11.09 мы пытались стабилизировать работу внучную удаляя строки, используя стандартный подход DELETE from .., однако activity_logs не имело индекса по столбцу timestamp,
по которому мы пытались вести удаление. Это приводило к полному прочитыванию всех строк в таблице, а на момент инцидента у нас было порядка 5 миллионов записей. Из-за этого удаление даже
10000 строк вызывало серьезные трудности и значительную деградацию производительности: команды удаления выполнялись от 50 до 360 секунд.
Нами было принято решение обновить кластер (так как текущая версия уже подошла к EOL), и вместе с этим заново попытаться использовать DELETE запрос. После переноса мы попытались произвести
данную операцию, однако она по-прежнему выполнялась значительное количество времени. По итогам обсуждений мы приняли решение о полной очистке таблицы: для этого сделали новую пустую таблицу, и с помощью RENAME подменили основную таблицу свежесозданной.
Это помогло, и мы приняли решение закрыть инцидент.
Диагностика
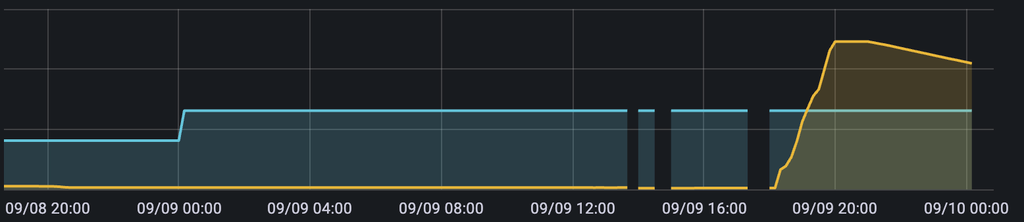
// графики //
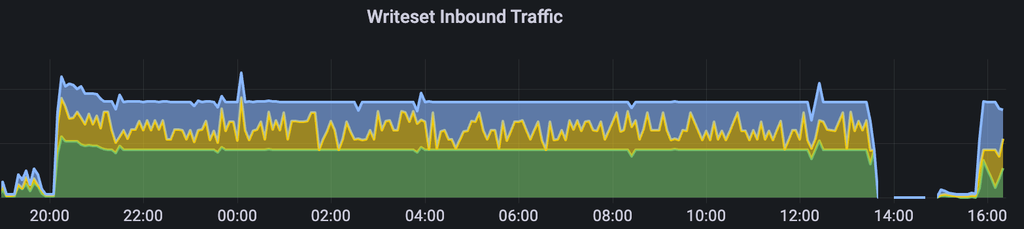
увеличение входящего трафика на кластер баз данных
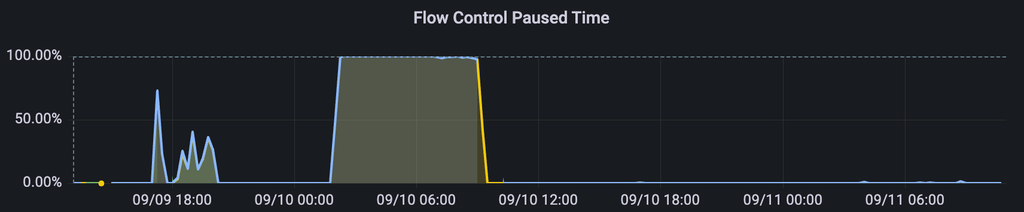
flow control paused time на 100% - мы не можем обработать новые входящие SQL запросы, так как заняты выполнением текущих
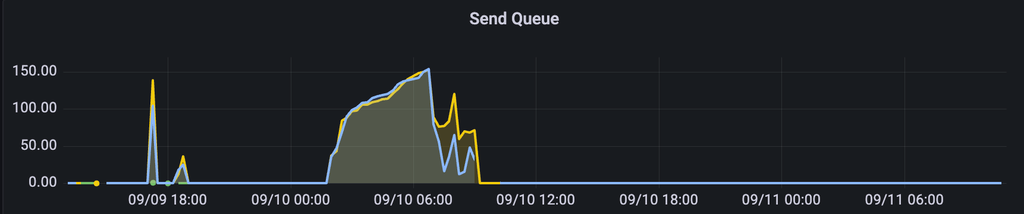
как результат предыдущему графику, у нас копится очередь по входящим (receive), так и по исходящим (send) очередям
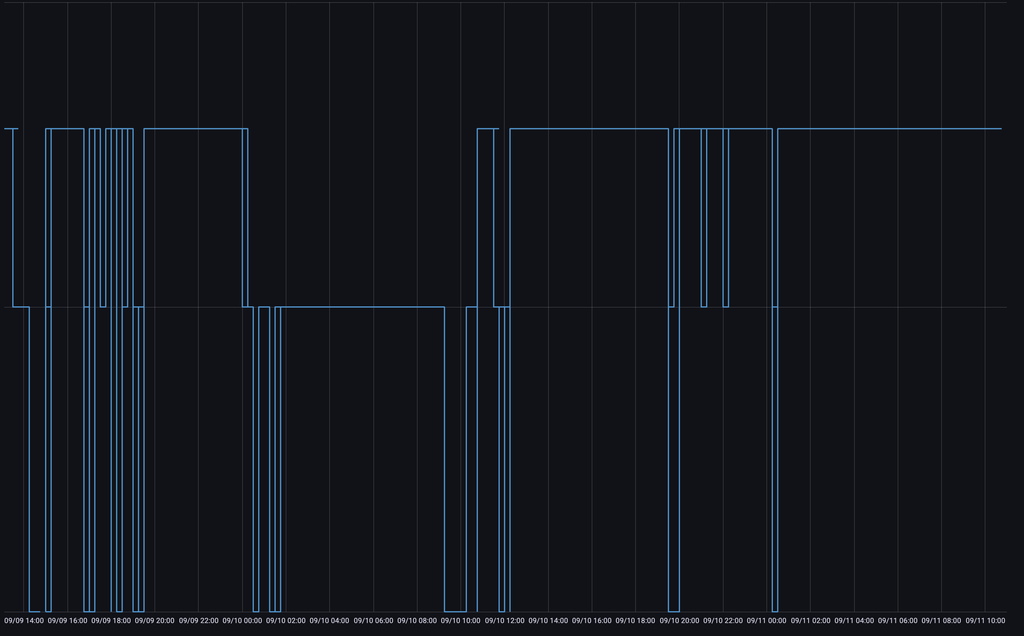
график, показывающий объем кластера: чем ниже, тем меньше нод активно (всегда должен быть ровным, такие флуктуации - признак отвала мастеров или слейвов)
рост места, занимаемого базой данных: совпадает со временем большого числа INSERTов
Меры предотвращения
// что сделать, чтобы не повторилось//
Мы рассматриваем возможность о написании своего сервиса сбора и анализа логов поверх clickhouse или cassandra - баз данных, которые заточены под хранение больших данных. Пока что у нас нет другого решения кроме как повторения процесса очистки, если инцидент повторится
Какие сервисы затронуты
// список сервисов //
Частично или полностью были недоступны:
- panel.superhub.host
- pay.superhub.host
- api.superhub.host
При подсчете SLA мы сообщаем следующие показатели: в течение последних 7 дней superhub.host - 99.6%, pay.superhub.host - 99.1%, panel.superhub.host - 94.6%.
Приносим свои извинения из-за недоступности сервисов.