LSR / Деградация сервисов хостинга / 08.02.24
Описание
// вкратце что произошло//
В связи с урезанием максимальной скорости канала до 15Mbit/sec провайдером мы начали получать большое количество packet loss. В связи с этим наблюдались перебои в доступности сайтов и нод, находящихся в кластере суперхаба. При этом внутренняя связность нарушена не была.
Предпринятые действия
// таймлайн с описанием //
- 08.02.24 14:30 регистрируем первые потери пакетов от мониторинга
- 08.02.24 14:45 предполагаем возможный DDoS на инфраструктуру
- 08.02.24 15:00 начинаем изучать графики flow и различные возможные метрики, это все меньше начинает походить на DDoS
- 08.02.24 16:00 связываемся с провайдером и начинаем процесс перезагрузки сетевого оборудования
- 08.02.24 16:20 получаем ответ от провайдера: "фиксируем нагрузку на сеть. как только нагрузка будет снята, всё восстановится"
- 08.02.24 16:30 и до самого позднего вечера мы начинаем различные тесты по нагрузке сети. далее смотрите анализ и разбор
- 09.02.24 01:30 митигируем проблему путем переключения на резервного провайдера вспомогательными системами
- 09.02.24 12:00 ситуация не разрешилась даже при минимальной нагрузке, принято решение о полноценном переключении на резерв
- 09.02.24 12:30 полностью переключаемся на резервного провайдера и делаем его основным, сайты хостинга полностью доступны и мы начинаем восстановительные работы на нодах
- 09.02.24 14:00 завершаем работы на нодах и на инфраструктурных сервисах
Анализ
// анализ описания //
В связи с тем, что нам не сообщалась никакая дополнительная информация о том, с какой стороны была "повышенная нагрузка", мы не могли понять ни ее причины, ни следствие и не могли разобраться, что нам делать. Фактически мы искали иголку в стоге сена с таким количеством возникающих проблем. Несмотря на ситуацию мы смогли обеспечить работу сайтов хостинга для всех клиентов, чьи сервера находились не на локациях в кластере суперхаба. У нас работали как прием платежей, так и основной сайт с панелью. В этом случае мы переключились на двух резервных провайдеров, которые обрабатывали http-трафик, а сами начали полноценное расследование ситуации.
Вечером стало понятно, что наша ситуация не решится сама собой, и мы решили постепенно отключать все не критичные системы: ноды кластера, k8s-dev, а также оставшиеся сервисы, которые не влияли на работоспособность наших сайтов. В какой-то момент ситуация улучшилась: мы постоянно проверяли ping с внешней площадки до суперхаба, и при практически полном выключении заметили 0 packet loss. Это и оказалось на следующий день ответом на вопрос, что случилось.
Не понимая всей картины и почему происходит это поведение сетевого оборудования, ночью мы переключили часть трафика на резервный канал для восстановления работоспособности вспомогательных систем: мониторинга, бота поддержки для ВК, трекера и так далее. С утра мы продолжили расследование и пришли к следующим выводам: при полноценном выключении всех серверов мы попытались скачать любой файл из интернета и при легитимной скорости нашего канала в гигабит получили скорость в 15(!!!!) мегабит в секунду. И эта скорость не возрастала со временем. Более того, при повторном включении линков всех наших гипервизоров, они начали генерировать нагрузку на сеть, и с внешней площадки мы начали получать очередные packet loss. Они достигали примерно 60% от общего числа отправленных пакетов.
Днем мы переключились на резервного провайдера, который, оказалось, стал стабильнее прежнего. Мы до сих пор расследуем причину, но так и не смогли до конца ее понять. Составили претензию провайдеру и ждем информации о ее решении. Сейчас все системы суперхаба работают в штатном режиме, мы сменили основной IP для пользовательских нод - и это единственная потеря и изменение, которое произошло за прошедшие сутки.
Диагностика
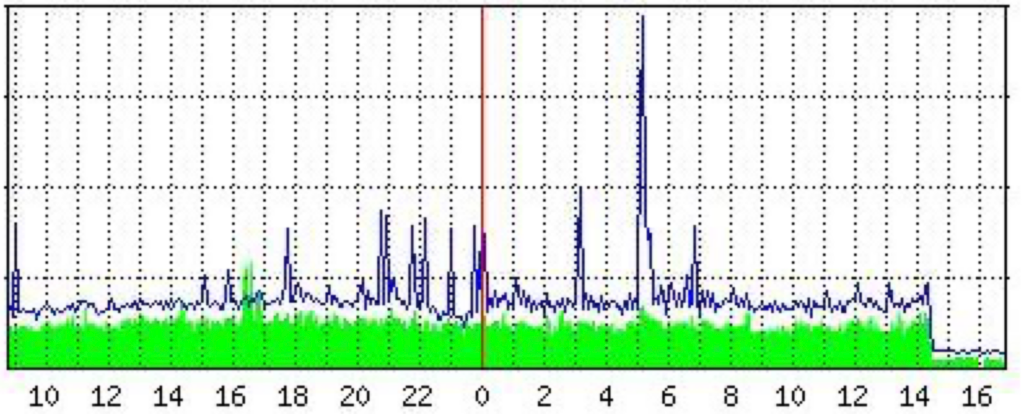
// графики //
график падения сетевого трафика в два раза в момент, когда нам начали его шейпить
Меры предотвращения
// что сделать, чтобы не повторилось//
Мы слаженно отреагировали и до последнего оттягивали момент смены IP-адресов, однако это стало неизбежным процессом. В данном случае мы не видим каких-либо новых мер предотвращения кроме как смену одного из провайдеров, который запросто может отключить или порезать нам трафик. Мы также рассматриваем необходимость более быстрого оповещения наших клиентов о любых глобальных проблемах на кластере через нашу поддержку, оповещения во все основные соц.сети (телеграм, вк и дискорд) и плашку на нашем статусе https://status.superhub.host
Какие сервисы затронуты
// список сервисов //
Работа с перебоями и очень плохой связью:
- пользовательские сервера на ноде west
- пользовательские сервера на ноде horizon
- пользовательские сервера на ноде generation
- пользовательские сервера на ноде zero
- пользовательские сервера на ноде rain
- пользовательские сервера на ноде dawn
Бесперебойная работа сайтов, выключения в моменты тестирования нагрузки на сеть:
- superhub.host
- panel.superhub.host
- pay.superhub.host
При подсчете SLA мы сообщаем следующие показатели: наши сайты в течение последних суток имели SLA 96%, что соответствует максимальному простою в течение часа (суммарно). Конечно, этот показатель также недопустим для нас, однако мы сделали всё возможное, чтобы его не опустить еще ниже.
Мы по-прежнему решаем проблемы, связанные с текущим переключением провайдеров, и восстанавливаем доступ к ряду инфраструктурных сервисов, находящихся на других площадках. Эти работы не затрагивают продакшн и не влияют на сайты или производительность нод.
Приносим свои извинения из-за недоступности сервисов. Согласно нашей оферте, мы начислим компенсацию в размере стоимость работы сервера в день, умноженную на два